Tool Calling(工具调用)
Agent 不只聊天——它们能动手做事。虾饺提供 7 个内置工具,全部开箱即用;与 Agent 持久记忆、RAG 知识库、外部平台集成 配合使用时能力更完整。
Agent 实时调用 memory_search 回忆上下文,memory_write 持久化洞察 — 全过程可见。
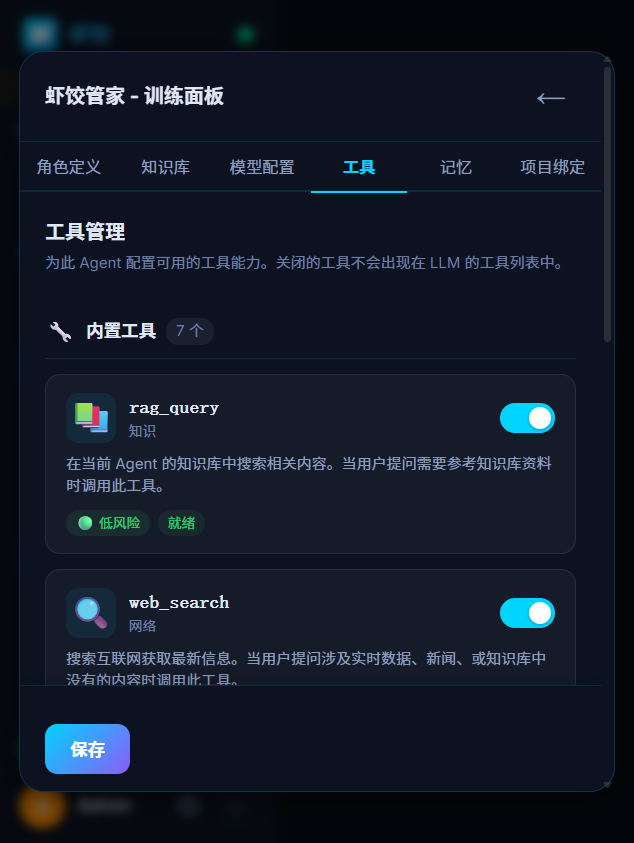
工具管理面板 — 为每个 Agent 独立配置可用工具,支持一键开关
工作原理
Tool Calling 实现了一个完整的 LLM 调用循环。Agent 不是一次性回复,而是"思考—行动—观察—再思考"的循环:
┌──────────────────────────────────────────────────────┐
│ │
│ 用户消息 │
│ ↓ │
│ LLM 推理:需要工具吗? │
│ │ │
│ ├─ 否 → 直接生成回复 → 发送给用户 │
│ │ │
│ └─ 是 → 生成工具调用请求 │
│ ↓ │
│ 执行工具(可能多个) │
│ ↓ │
│ 工具结果回注到上下文 │
│ ↓ │
│ LLM 再次推理(可能再次调用工具) │
│ ↓ │
│ 最终回复 │
│ │
└──────────────────────────────────────────────────────┘透明可见
整个过程对用户完全透明——聊天界面实时显示 Agent 正在调用哪个工具、传入了什么参数、返回了什么结果。不是黑箱。
7 个内置工具详解
1. web_search — 网络搜索
Agent 可以搜索互联网获取实时信息。
| 属性 | 说明 |
|---|---|
| 引擎数量 | 6 个 |
| 引擎列表 | auto / DuckDuckGo / Brave / Kimi / Perplexity / Grok |
| 模式 | auto 模式自动选择可用引擎 |
| 故障切换 | 一个引擎失败自动尝试下一个 |
使用场景:
你:@代码助手 Node.js 22 有什么新特性?
代码助手:[调用 web_search: "Node.js 22 new features"] → 获取搜索结果 → 整理回复2. rag_query — 知识库检索
从你上传的文档中检索相关信息。
| 属性 | 说明 |
|---|---|
| 检索方式 | BM25 + 向量混合检索 |
| 排序 | RRF 融合 + LLM 重排序 |
| 分块 | 200 字小块 + 800 字大块 |
使用场景:
你:@代码助手 我们的 API 认证方式是什么?
代码助手:[调用 rag_query: "API 认证方式"] → 从你上传的 API 文档中检索 → 精准回答详见 RAG 知识库。
3. memory_write — 写入持久记忆
Agent 主动把重要信息写入持久记忆。
| 属性 | 说明 |
|---|---|
| 记忆类型 | semantic / episodic / procedural |
| 存储方式 | embedding + SQLite |
| 去重 | embedding 相似度去重,防止重复存储 |
使用场景:
你:我是后端开发,主要用 Python,公司用 AWS
代码助手:[调用 memory_write: type="semantic", content="用户是后端开发,主要用 Python,公司用 AWS"]
→ 下次对话时自动记住这些偏好4. memory_search — 搜索记忆
检索 Agent 的持久记忆。
使用场景:
你:我上次让你帮我查的那个部署方案是什么来着?
代码助手:[调用 memory_search: "部署方案"] → 找到之前的记忆 → 回忆并回答详见 Agent 持久记忆。
5. call_agent — 跨 Agent 调用
一个 Agent 可以调用另一个 Agent 完成子任务。
| 属性 | 说明 |
|---|---|
| 嵌套保护 | 最多 3 层(A→B→C 允许,A→B→C→D 拒绝) |
| 调用方式 | 指定目标 Agent ID + 消息内容 |
| 返回值 | 被调用 Agent 的完整回复 |
使用场景:
你:@代码助手 帮我写一个 README 的英文版
代码助手:好的,我先写中文版,然后调用翻译官翻译。
[调用 call_agent: agent="translator", message="请把以下 README 翻译成英文:..."]
翻译官:[返回英文翻译]
代码助手:这是完整的英文 README:...嵌套保护
3 层嵌套限制是为了防止 Agent 之间无限递归调用(A 调 B、B 调 A、A 又调 B...)。
6. manage_channel — 渠道管理
管理外部平台连接器——让 Agent 能接入飞书、钉钉等平台。平台能力与配置步骤见 外部集成。
| 操作 | 说明 |
|---|---|
| 创建连接器 | 配置平台类型和认证信息 |
| 启动 | 开始监听外部平台消息 |
| 停止 | 暂停监听 |
支持的平台:飞书(Lark)/ 钉钉 / 企微 / Telegram
7. manage_schedule — 定时任务
让 Agent 按 Cron 表达式定期执行任务。
| 属性 | 说明 |
|---|---|
| 语法 | 标准 Cron 表达式 |
| 示例 | 0 9 * * 1 = 每周一上午 9 点 |
| 能力 | 创建 / 删除 / 列出定时任务 |
使用场景:
你:@虾饺管家 每天早上 9 点给我一份新闻摘要
虾饺管家:[调用 manage_schedule: cron="0 9 * * *", task="新闻摘要"]
→ 每天 9 点自动触发,搜索新闻并发送摘要工具权限配置
每个 Agent 可以独立配置允许使用的工具:
{
"id": "coder",
"name": "代码助手",
"tools": {
"allow": ["web_search", "memory_write", "memory_search", "rag_query"]
}
}最佳实践
- 虾饺管家:开放所有工具(系统管理需要)
- 创作类 Agent(小说家/编辑):只开 memory,避免搜索干扰创作
- 技术类 Agent(代码助手):开 web_search + rag_query + memory
- 翻译类 Agent:开 web_search(查术语)+ memory
与其他平台 Tool Calling 的对比
| 虾饺 | Dify | Coze | |
|---|---|---|---|
| 内置工具 | 7 个 | 10+ | 100+ 插件 |
| 自定义工具 | HTTP 工具(零代码)+ JS 自动注册 + MCP | 代码节点 | 插件开发 |
| 工具调用可见性 | ✅ 实时显示调用过程 | ✅ | 部分可见 |
| 跨 Agent 调用 | ✅ call_agent | ❌ | ❌ |
| 按 Agent 权限(ACL) | ✅ | ✅ | ✅ |
| 可扩展性 | 三种方式;HTTP 工具无需重启 | API + 配置 | 插件开发 |
虾饺的工具插件数量不如 Coze 多,但强调跨 Agent 调用、完全可见的工具轨迹,以及零代码 HTTP 工具扩展。
工具调用的实际输出
以下是虾饺 Web 界面中 Tool Calling 的真实展示效果:
你:@代码助手 最新的 Bun 和 Node.js 性能对比数据
代码助手:让我搜索最新的对比数据。
🔧 正在调用 web_search...
├── 查询: "Bun vs Node.js performance benchmark 2026"
├── 引擎: Google
└── ✅ 找到 8 条结果
根据最新的基准测试数据(2026 年 3 月):
| 指标 | Node.js 22 | Bun 1.x |
|------|-----------|---------|
| HTTP 请求/秒 | ~45,000 | ~78,000 |
| 启动时间 | ~50ms | ~8ms |
| 内存 (Hello World) | ~40MB | ~20MB |
| npm install 速度 | 1x | ~3x |
注意:实际性能取决于工作负载类型。Node.js 在长时间运行的服务中...
🧠 正在写入记忆...
└── ✅ 已记住: "用户关注 Bun vs Node.js 性能对比"每个工具调用都在聊天界面实时显示进度,用户可以清晰看到 Agent 的"思考过程"。
自定义工具
除 7 个内置工具外,虾饺提供三种方式扩展工具:
方式一:HTTP 自定义工具(零代码)
将任意 HTTP API 配置为 Agent 工具——无需写代码,在 设置 → HTTP 工具 中填表即可。
| 属性 | 说明 |
|---|---|
| URL | 支持 |
| 方法 | GET / POST / PUT / DELETE |
| 请求头 | 自定义(如 Authorization) |
| 请求体 | 含 |
| 响应提取 | 点路径表达式选取返回字段(如 fields.summary),不是 JSONPath |
示例 — JIRA 工单查询:
{
"name": "jira_get_issue",
"description": "按工单号查询 JIRA Issue",
"url": "https://your-domain.atlassian.net/rest/api/3/issue/{{issueKey}}",
"method": "GET",
"headers": { "Authorization": "Basic {{token}}" },
"parameters": [
{ "name": "issueKey", "type": "string", "description": "如 PROJ-123", "required": true },
{ "name": "token", "type": "string", "description": "Base64 凭证" }
],
"responseExtract": "fields.summary"
}配置一次后,可在任意 Agent 上启用;LLM 会像调用内置工具一样调用它。定义保存在 data/http-tools.json,界面在 设置 → HTTP 工具。
方式二:JS 自动注册(丢文件)
将 .js 文件放入 server/services/tools/(内置)或 data/custom-tools/(用户自定义)。工具注册表在启动时扫描这两个目录并自动注册各模块。
// data/custom-tools/my_tool.js
export default {
description: "查询公司内部系统",
parameters: {
type: "object",
properties: {
system: { type: "string", enum: ["crm", "erp", "jira"] },
query: { type: "string", description: "查询内容" }
},
required: ["system", "query"]
},
handler: async ({ system, query }) => {
const result = await internalAPI.query(system, query);
return { data: result };
}
};文件名即工具名:my_tool.js → 工具名 my_tool。新增文件后需重启服务以加载。
集中管理见 server/services/tool-registry.js,支持按 Agent 的允许/拒绝列表(ACL)。
方式三:MCP 桥接工具
连接外部 MCP 服务器(stdio 或 HTTP),其工具会自动以 mcp:{serverId}:{toolName} 的形式注册。
在 设置 → MCP 中配置 MCP 服务;虾饺通过 JSON-RPC 能力协商发现工具并完成注册。
该选哪种?
- HTTP 工具:最快——零代码、界面配置,适合 REST API
- JS 自动注册:最灵活——完整 Node.js 能力、异步逻辑、自定义鉴权
- MCP 桥接:适合已提供 MCP 服务的复杂外部系统